

김재후 (Jaehoo Kim)
M.S. Course
Research Topic: EEG+ Virtual Reality | Synthetic Data Generation
E-mail: wogn0505@korea.ac.kr
Current Research
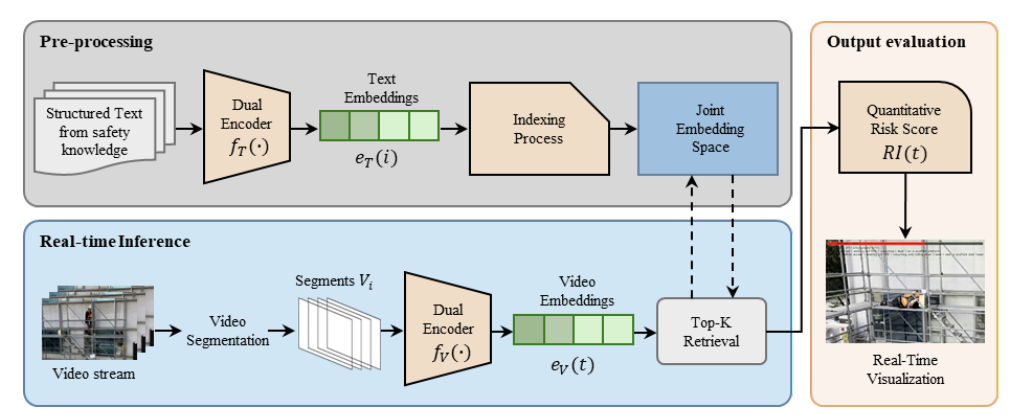
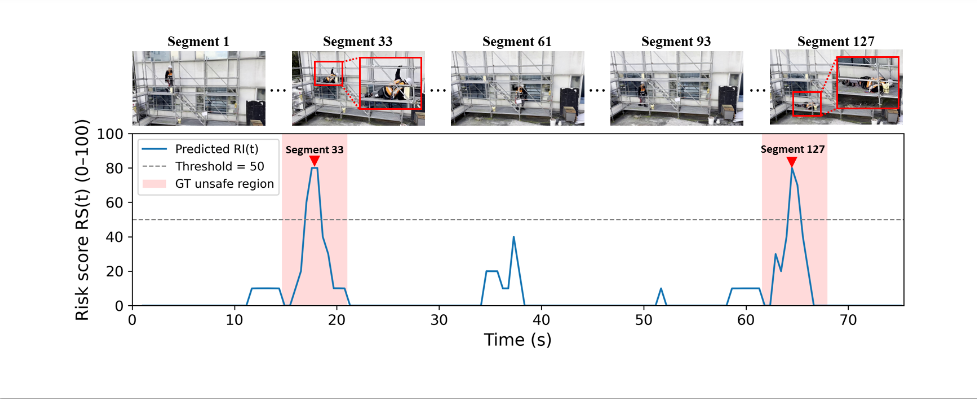
Interpretable Real-Time Construction Safety Monitoring via Video-Text Retrieval
Real-time construction safety monitoring on construction sites is increasingly implemented as rule-based logic over frame-level detections, but it often fails to remain reliable in practice. Because construction videos are highly variable (viewpoint/illumination changes, occlusions, motion blur, and frequent layout/equipment changes), detections fluctuate over time (“temporal inconsistency”), which causes alarms to oscillate and errors to accumulate as false positives and false negatives. Moreover, frame-wise decisions provide limited, inspectable evidence about why a scene is judged as hazardous—especially when risk is determined by temporal relationships among workers, PPE compliance, actions, objects, and locations rather than a single-frame cue. As a result, simply stabilizing outputs or adding more heuristic rules may not resolve recurring misjudgments or build operator trust in deployment.
To address this reliability–interpretability gap, this study does not rely on per-frame verdicts or repeated text decoding. Instead, it represents safety knowledge as a structured text bank and interprets streaming scenes via video–text retrieval in a shared embedding space. Specifically, based on the need to ground decisions in relationships among risk cues (A), the framework constructs a five-field text bank—SUBJECT / SUBJECT_STATE(PPE) / ACTION / OBJECT / LOCATION —and labels texts containing explicit fall-related risk cues as unsafe using rule-based procedures grounded in OSHA guidance and AI-Hub work-at-height data (B,C). It then aligns segment-level video embeddings and text embeddings using a pretrained video–text dual encoder and pre-indexes the text embeddings with FAISS for low-latency retrieval (B,C). During operation, the stream is processed in 2.0 s segments with a 0.5 s stride, retrieves top-K evidence texts per update, and computes a Risk Score RS(t) as the similarity-weighted proportion of unsafe evidence; simultaneously, top evidence captions are overlaid so operators can verify the triggering cues (D). Experiments on a real scaffold clip demonstrate conservative alarms (Accuracy 86.43%, Precision 1.00) with high semantic alignment between retrieved evidence and GT descriptions (BERTScore-F1 ≈ 0.895), while end-to-end mean latency (210.8 ms) stays below the 500 ms update stride—supporting real-time operation on a single GPU without site-specific retraining.